-
Debt Dictionaries

When a company speaks, who hears what? We demonstrate that equity investors interpret earnings calls through a lens of growth and technology, while debt investors systematically emphasize news about economic challenges and liquidity. This holds true even when their financial interests seem to converge.
Authors:
Jawad Addoum, Vitaly Meursault, Justin Murfin
Status:
Working Paper
Updated:
Nov 2024
-
LLMs Redefine Quality Panel Creation from Diverse Table Scans: Pipeline and Evaluation Using State-Level Early Car Adoption Tables

Multimodal LLMs are a breakthrough in converting historical tables into usable data. Currently, researchers must either manually digitize tables (time-consuming) or build specialized deep learning systems (requiring technical skills). LLMs allow researchers to use their domain expertise through simple English instructions instead of complex coding, adapting methods to particular document sets easily. Researchers demonstrate that an LLM-based pipeline produces highly accurate results, confirmed by comparing against human-processed data as a reference point. Testing on vehicle registration records, this method is 100× cheaper than outsourcing while reducing errors from 40% to 0.3%. Results match human-validated data quality, making historical economic research more accessible to non-technical experts.
tags:
Authors:
Ina Ganguli, Jeffrey Lin, Vitaly Meursault, Nicholas Reynolds
Status:
Working Paper
Updated:
Aug 2024
-
Patent Text and Long-Run Innovation Dynamics: The Critical Role of Model Selection

Text-based measures in economic research can be highly sensitive to model choice, potentially leading to contradictory conclusions. We demonstrate that domain-specific validation for model selection is critical for reliable analysis of technological change and innovation dynamics. As NLP models become increasingly powerful and accessible to economists, we can and should spend more time on selection and validation.
tags:
Authors:
Ina Ganguli, Jeffrey Lin, Vitaly Meursault, Nicholas Reynolds
Status:
Working Paper
Updated:
Aug 2024
-
PEAD.txt: Post-Earnings-Announcement Drift Using Text
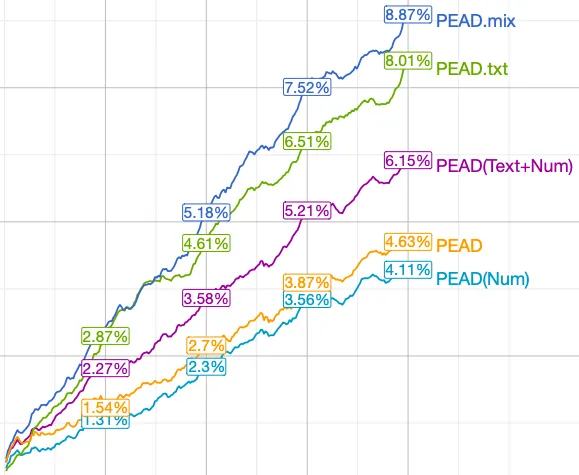
Post-earnings announcement drift (PEAD) is one of the best known anomalies in Finance: Buy stocks with positive earnings surprises and sell stocks with negative earnings surprises, and you will keep making money on the drift. We show that you can generate a much larger drift (PEAD.txt) without even using the earnings number, but using the text of earnings call instead. There is much more to earnings calls than earnings number.
Authors:
Vitaly Meursault, Pierre Jinghong Liang, Bryan R. Routledge, Madeline Marco Scanlon
Status:
Published at JFQA (2023)
Updated:
Sep 2023